파이썬을 활용한 금융 분석 - Python for Finance

파이썬으로 금융 분석을 하고 싶은 입문자와 특히 파이썬 초심자에게 이 책을 추천하고 싶다.
그 이유는 다음과 같다.
1. 파이썬의 기초 문법/자료구조 내용을 다룰뿐만 아니라, numpy와 pandas 그리고 데이터 시각화까지 두루두루 기초를 다질 수 있다.
2. 시계열 데이터를 다루는 여러가지 방법을 소개하며, 금융 데이터 과학에 대해 (비전공자에게) 친절하게 설명되어있다.
3. 단순히 문법과 함수 사용법만 알려주는 것이 아니라, SQL 데이터베이스 상에서 입출력 작업을 하는 방법, 파이썬의 성능을 개선할 수 있는 방법을 소개하며 "금융 분석에만 초점을 두지 않는다.
책의 구성은 `파트`라는 대분류 아래 `장`이라는 중분류로 구성이 되어있다.
`Part 1 파이썬과 금융`, `Part 2 파이썬 기초 정복`, `Part 3 금융 데이터 과학`, `Part 4 알고리즘 트레이딩`으로 구성되어 있으며
part 1 ~ 3까지는 프로그래밍 및 통계 공부를 했던 분이라면 충분히 따라갈 수 있는 내용이었지만, part 4는 매매 알고리즘이나 지수 공식같은 생소한 내용이 등장하면서 따라잡기 버거운 수준이었다.
(혹은 알고리즘 트레이딩에 큰 관심이 없어서 그런 것 일수도 있다.)
> `Part 1 파이썬과 금융`
`1장: 왜 금융 분석에 파이썬을 사용하는가` 임팩트 있는 첫 장이었다. 파이썬 공식 웹사이트(https://www.python.org/doc/essays/blurb/)에 있는 `What is Python?` 설명을 소개한다.
가장 마음에 드는 것은 `PEP20, Zen of Python`을 소개해줬다는 것이다. `import this`로 볼 수 있는 이스터에그이며, 파이썬의 철학을 담고 있다. (개인적으로 가장 마음에 드는 구절은 `Simple is better than complex`이다.)
금융 알고리즘을 구현하는데 수학적 문법이 유사한 특성 및 파이썬의 생산성 및 효율성에 대해 설명한다.
`2장 : 파이썬 기반구조`에서는 파이썬 개발환경 구성에 초점을 둔다.
미니콘다, 도커 컨테이너, 주피터 노트북, 클라우드 등 설치 방법과 사용법에 대한 설명이 상세하게 기술되어 있다.
> `Part 2 파이썬 기초 정복`
`3장 : 자료형과 자료구조`, `4장 : Numpy를 사용한 수치 계산`,`5장 : pandas를 사용한 데이터 분석`, `6장 : 객체지향 프로그래밍`이 의외로 기대보다 탄탄한 예제로 구성되어있었다. 오랜만에 numpy, pandas를 사용해본 독자라면, 기억을 되돌리기에 충분한 분량과 설명이 담겨져 있다.

설명 - 코드 - 주석 형태로 구성되어있다.
> `Part 3 금융 데이터 과학`
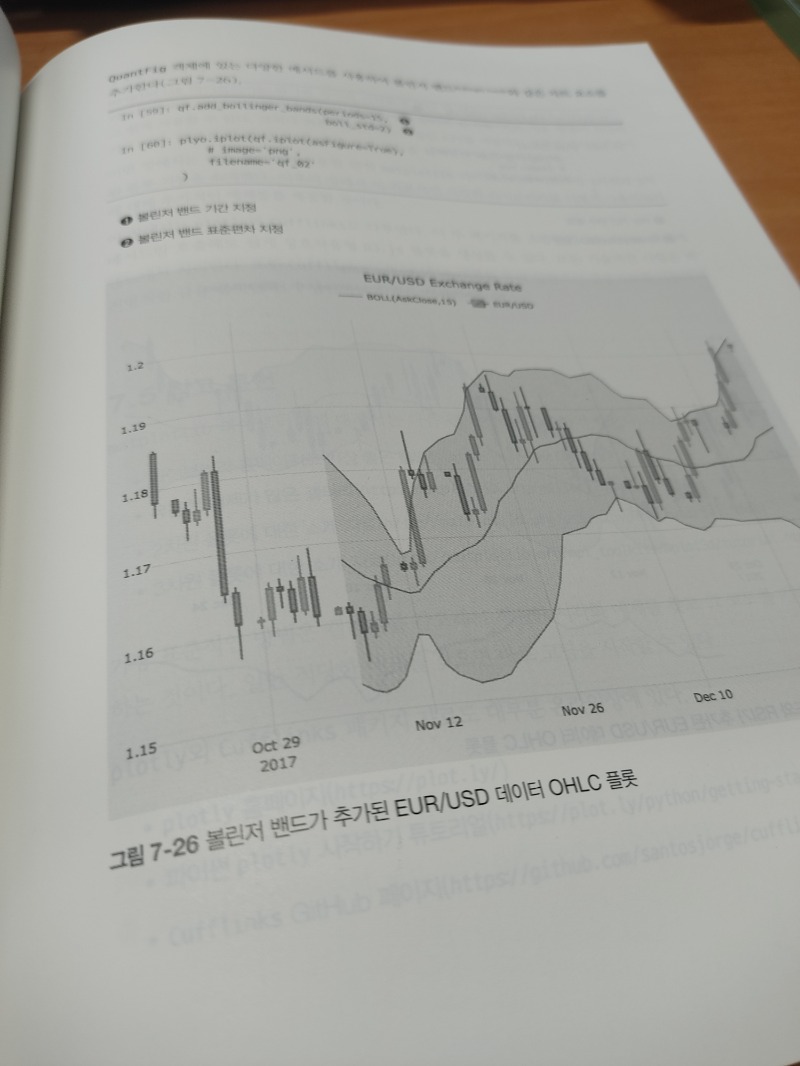
`7장 : 데이터 시각화`, `8장 : 금융 시계열`은 금융 데이터 과학에 필요한 그래프 작성법 및 시계열 데이터를 다루는 방법이 기술되어 있다. 금융 데이터는 시간에 따라 값이 변하는 시계열 데이터이고, 이 데이터를 시각화하는 것이 중요하다. (차트를 만들어 나만의 대시보드를 만드는 등, 금융 공학에서 필수적인 영역이다.) matplotlib과 plotly를 사용한 시각화 방법과 pandas를 이용한 시계열 데이터 처리에 대해 배울 수 있다.
`9장 : 입출력 작업`, `10장 : 파이썬 성능 개선`에서는 기본 파이썬 입출력 작업, 텍스트 파일 읽고 쓰기, SQL 데이터베이스 작업, Excel/pytables를 이용한 입출력 방법에 대해 배운다. 아울러 파이썬에서 성능개선을 할 수 있는 몇 가지 방법(반복문 최적화, 벡터화, 알고리즘 최적화)에 대해 배운다.


매개변수마다 주석을 달아주어, 이해가 쉬웠다.
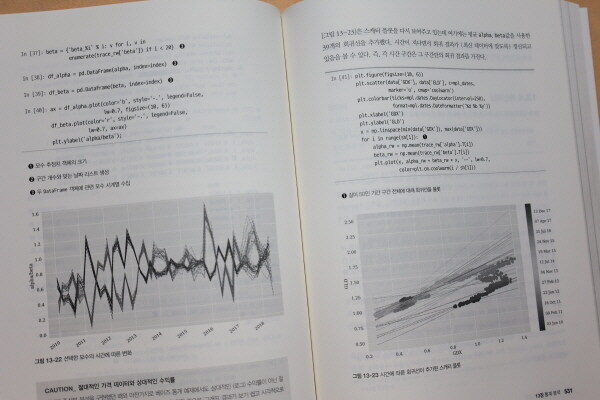
`11장 : 수학용 도구`, `12장 : 확률 과정`, `13장 : 통계 분석`에서는 금융 데이터 과학에서 사용되는 수학/통계 이론적 지식을 담고있다. 가장 피해가고 싶은 장이기도 했지만, 실제 데이터로 통계 분석을 하는 process를 따라가볼 수 있고 해당 코드 템플릿을 저장해두고 분석해본다면 추후 업무에 통계적인 자료 분석이 필요할 때 요긴하게 쓸 수 있겠다는 생각을 했다.
> `Part 4 알고리즘 트레이딩`
`14장 : FXCM 트레이딩 플랫폼`, `15장 : 매매전략`, `16장 : 매매 자동화` 이 세 장에서는 FXCM의 트레이딩 플랫폼 및 API를 사용해 트레이딩 전략을 배우고 실제로 매매 자동화를 구축해보는 내용이 담겨있었다. 특히 15장에서는 머신러닝을 사용하여 매매 전략 수립하는 방법에 대해 나와있는데, 해당 장의 탬플릿 코드를 사용하면 금융데이터가 아닌 다른 시계열 데이터 분석에도 유용하게 쓰일 것 같다는 생각을 했다. 회기분석, 클러스터링, 심층신경망 구축 등 머신러닝 기초 지식이 있으면 더 쉽게 이해가 되는 부분이었다.
> `Part 5 파생상품 분석`
이후 등장하는 `17장 : 가치 평가 프레임워크`, `18장 : 금융 모형 시뮬레이션`, `19장 : 파생상품 가치 평가`, `20장 : 포트폴리오 가치 평가`, `21장 : 시장 기반 가치 평가`는 금린이(금융어린이)인 내가 읽기에는 어려운 장이었다. 엄청나게 어려운 수식과 용어들이 등장했으며, 코드의 길이도 길고 복잡한 편이었다. 하지만 주석과 설명이 자세히 적혀있어서 코드의 흐름은 이해되는 편이었지만, 왜 저런 방법을 사용했는지는 알아채기가 어려웠다. 이해하기 위해서는 금융관련 전공 지식이 많이 필요할 것으로 예상된다. 마치 어려운 전공책을 보는 것 같았다.
이 책은 두껍다. 두꺼운만큼 많은 내용을 담고 있다. 하지만 평소 코딩과 Data Science에 관심이 많은 독자라면, `Part 3 금융 데이터 과학`까지는 재미있을 것이라고 생각한다. 특히 오랜만에 numpy, pandas를 사용한다면 그러하다. 내가 금융지식이 있었고, 알고리즘 트레이딩에 관심이 있었다면 이후에 나오는 부분도 따라갈 수 있었을 텐데.. 라는 아쉬움이 남는다. 하지만 금융 데이터 분석이라는 것이 이런 것이구나..를 느낄 수 있었다.
700 페이지가 넘는 이 책을 이해하기에는 내 소양과 독서 기간이 부족했다는 핑계를 대고 싶다. (사실 다 알고있다면, 왜 공부가 필요하겠는가?) 오늘도 나의 부족함을 느끼며 천천히 금융 공학을 공부해보려고 한다.
<이 리뷰는 한빛미디어 '나는 리뷰어다'로 부터 책을 지원 받아 작성되었습니다>